Overview
Condominio is a sound installation built into the stairwell of a 1958 residential building near Torre Velasca, the temporary home of Convey 2026. It distributes a fifty-minute choral composition vertically across five floors, assembled from the voices of fifty-two contributors who recorded themselves online. Each floor is assigned a register. The lower floors carry the denser, lower bands of the voice; the middle floors sit closer to speech; the upper floors thin out into the rarefied high register that opens onto the rooftop terrace. A visitor moving through the building doesn't encounter a piece so much as traverse one.
The title names what the building already is. A condominio is a specific Italian housing arrangement: shared vertical living, shared circulation, neighbors who know each other mostly through the sounds that leak between floors. Condominio treats the stairwell as the connective tissue of that arrangement, and the voices as its acoustic commons.
Brief

Convey is a design platform founded by Simple Flair in 2023, running for a week during Milan Design Week as an international event dedicated to contemporary design. The 2026 edition took over a five-floor residential building near Torre Velasca. Each apartment and room in the building was given over to a brand or designer presenting their work, so the common areas were the only spaces that connected the programs together. The event housed more than twenty international brands, among them USM, Completed Works, Cimento, Max Design, Terraformae, and Western Acoustics, alongside objects and spaces by designers including Patricia Urquiola, Stefan Diez, Panter & Tourron, and BIG-GAME, with Rooms Studio as guest designer. Bizzi & Partners served as main partner, with additional support from Levi's and Fever-Tree. The rooftop terrace was the event's social centerpiece.
The initial conversation, led on our side by Giulia Spitaleri, was open: Convey's team wanted sound in the common areas. No further specification. We visited the building and noticed immediately that the common areas people would actually spend time in weren't the landings or the terrace but the stairs themselves. The building's vertical circulation was going to be the site where visitors slowed down, got stuck behind each other, caught their breath between floors. It is also, in a residential building, where neighbors meet by accident: the informal social circuitry of the condominio, and the space where most of its unscripted encounters happen. Stairwells are notorious listening environments, full of long reverbs and hard surfaces, but those same qualities can make them among the most sonically memorable spaces in a building. We proposed the stairwell as the installation site, with all the acoustic difficulty that implied, and Convey agreed.
From kickoff to installation we had just over a month, a compressed window for a project covering concept development, contribution intake, composition, processing pipeline, sound system design, and install. Several of the decisions documented below were shaped by that constraint.
Concept
We brought in Furio Montoli to sharpen the architectural dimension of the project. Early conversations with him circled around a Jungian reading of the building: the house as a metaphor for the psyche, with each floor corresponding to a stratum of consciousness. That gave us a structural logic to work against. We explored the idea of distributing a single piece of music across the building by frequency band, with low frequencies dense at the ground floor and the spectrum thinning as you climbed.
The frequency-band approach ran into a physical limit early on. The installation couldn't accommodate a subwoofer, which meant the low end of the intended spectrum wasn't available to us. While we were working out what to do with the constraint, Luca Rigat suggested the voice as an alternative register map, referencing a 2020 project Thomas Feriero had worked on for Fendi where stacked vocals had done similar structural work.
The substitution reorganized the piece. Voices mapped onto a stairwell more cleanly than an abstract spectrum did. The range divisions became musical rather than acoustic (low voices at the ground floor, speech-adjacent registers in the middle, rarefied upper voices toward the terrace), and the Jungian logic of ascent was preserved by reframing it as a passage through the human vocal range instead of the frequency spectrum. Furio stayed involved throughout, and the collaboration stayed cross-disciplinary throughout without resolving into a neat handoff.
Once the piece was built around the voice, a second logic emerged. Convey exists to bring designers, brands, and audiences into proximity with each other. An installation built from contributed voices embodied that proposition in acoustic form. We extended the concept to gather the voices publicly and attribute them individually, so the piece would accumulate a community as it was built.
Contribution system
Before writing any music, we built the contribution system. It had to be friction-free to get a usable volume of voices in the time available, and Thomas built the first working version over a weekend before any notes were written.
Contributors visited a mobile-first web app that presented a scale, one note at a time. Each note could be previewed as a reference tone, then recorded by the contributor. The instructions asked them to "hum or sing," and we kept the prompt deliberately loose. In practice, contributors did a wide range of things: sustained notes, syllables, hummed tones, spoken fragments, and in at least one case, beatboxing. We decided early on to preserve the full range of interpretation rather than filter it.


The scale was heptatonic. We defaulted to octave 4, with an option to record additional octaves for contributors comfortable doing so. We tested varying the requested octave dynamically, but observed that non-singers reliably defaulted to their own natural register regardless of what we asked for. We stopped trying to direct the octave and started measuring it in post instead.
An early version of the interface included a real-time tuner. We removed it after observing that it discouraged contributors more than it helped them. Pitch correction moved to the backend, with a deliberate decision to nudge rather than fix: we preserved most of the pitch variation within each recording, correcting only the overall center of the note.
The stack was a Next.js frontend, a Cloudflare Worker to handle ingestion and upload, and a Linux server at the studio for processing. Device compatibility took continuous iteration throughout the contribution window. Several Android models refused getUserMedia calls for WebM audio; others applied limiters or compressors that altered the raw recordings. We shipped small fixes throughout the intake window and preserved every submission in its original form, so any corrections could be made in post rather than lost.
Processing pipeline
The pipeline ran nightly on the studio server and rebuilt the playable sampler instrument from scratch each morning. It assumed nothing about the contributor's pitch accuracy or the requested note.
Each submission passed through four stages. Transcoding normalized every file to canonical raw WAV at 48kHz, mono, 16-bit, caching by filename so re-runs were cheap. Pitch detection used aubiopitch with the YIN-FFT algorithm, filtered to the 50–2000 Hz range. The median of the per-frame fundamental frequency was taken as the nominal pitch, with an IQR-trimmed cents standard deviation computed as a confidence metric. Recordings with a standard deviation above 100 cents, or fewer than ten pitched frames, were rejected. The detected pitch was converted to an exact MIDI note via 12·log2(f/440) + 69, rounded to the nearest semitone, with the residual offset in cents recorded. If a contributor clicked D4 but sang E, the file was catalogued as E.
Correction and normalization came next. Rubberband shifted each sample by its measured offset to land exactly on the target semitone, and EBU R128 loudness normalization (I=-16, TP=-1.5, LRA=11) brought every contributor to comparable playback levels in the sampler. The mapping stage grouped samples by their detected note, absorbed under-populated notes into their nearest well-populated neighbors (to keep round-robin playback from thinning out), and filled in keyranges by midpoint between adjacent sampled notes. The outermost notes padded outward by twelve semitones so the instrument covered more of the keyboard than the raw material did.
The pipeline emitted two sampler preset formats (SFZ and Decent Sampler) against a shared samples/ folder, plus a mapping.json sidecar recording which contributor appeared on which note and a contributor display-name table. Each key press in the final instrument pulled randomly from the samples assigned to that note, so no two playbacks were identical.
Composition
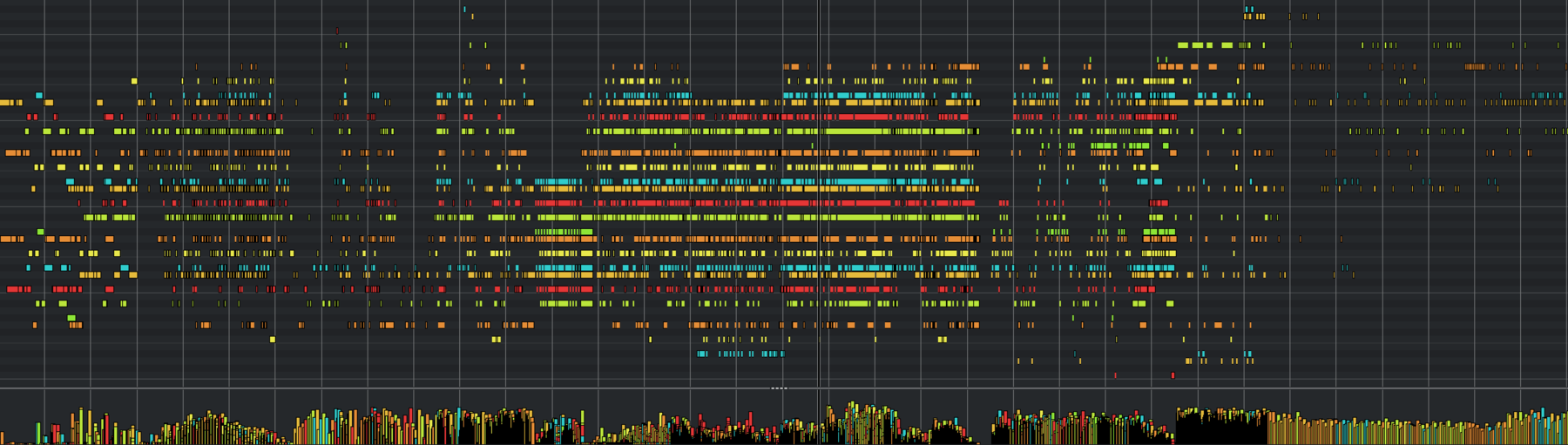
Composition began with around thirty voices. A script ran every morning to rebuild the sampler from the latest contribution pool, which meant the instrument under our hands mutated daily. Some mornings the sampler was more out of tune; some mornings a strong singer contributed and the composition abruptly turned beautiful.
The piece was authored in Interval, an internal programming language we've developed for compositions with evolving harmonic and rhythmic structure.
It allowed quick iteration of ideas through an algorithm-like approach to music. An example:
// Interval 0.7
// Condominio — sample eight-speaker routing over eight bars.
@ppq 480
@bpm 50
@ts 4/4
@bars 8
@seed 217
@title "Condominio"
// A chromatic descent in a minor context — modal centres slide
// under a mostly static vertical field.
@scale root=C mode=minor * 4 | root=B mode=minor * 2 | root=A mode=phrygian
@harmony
i | i | iv | iv
i | bVII | bVI | i
// ---- patterns ---------------------------------------------------
@pattern rest unit=1/1
.
// Floor 4 · Lower — upper cluster, enters late, breathes
@pattern f4l unit=1/2
.
{^2+^3+^4, ^2+^4, ^3+^4}[vel:58 prob:0.7]
// Floor 3 · Upper — the most active middle voice, evolves
@pattern f3u unit=1/4
^6+^7+^1[vel:72]
~
{^6+^1, ^7+^1, ^6+^7+^1}[vel:66]
~
// Floor 3 · Lower — sustained third/fourth interval with agogic lean
@pattern f3l unit=1/2
^3+^4[vel:70]
~
// Floor 2 · Upper — doubled with F3·Upper an octave down, thinner
@pattern f2u unit=1/4
^7+^1[vel:64 prob:0.85]
~
~
{^1, ^7+^1}[vel:60]
// Floor 2 · Lower — bass cluster foundation, steady
@pattern f2l unit=1/1
^4+^5+^6[vel:80]
// Floor 1 · Upper — the deepest sustained band
@pattern f1u unit=1/1
^1+^2+^3[vel:78]
// ---- tracks -----------------------------------------------------
@track floor_4_upper ch=1 oct=5
play: rest
@track floor_4_lower ch=2 oct=5 gate=0.95
play: f4l -> vary(0.4) -> swell(0.6, arch) -> humanize(25ms, 0.4)
@track floor_3_upper ch=3 oct=4 gate=0.9
play: f3u -> evolve(0.12) -> humanize(15ms, 0.3) -> vel_curve(wave=sine, min=55, max=82, repeat=2)
@track floor_3_lower ch=4 oct=4 gate=0.92
play: f3l -> agogic(2, 5, 8) -> humanize(20ms, 0.25)
@track floor_2_upper ch=5 oct=3 gate=0.88
play: f2u -> vary(0.3) -> humanize(18ms, 0.35)
@track floor_2_lower ch=6 oct=3 gate=0.96
play: f2l -> swell(0.5, ease_in_out) -> humanize(30ms, 0.3)
@track floor_1_upper ch=7 oct=3 gate=0.96
play: f1u -> humanize(30ms, 0.3)
@track floor_1_lower ch=8 oct=2
play: rest
The original intention was generative and live: contributions would flow continuously into the sampler, round-robin playback would differentiate each pass through the composition, and visitors would be able to record their voice on-site and hear themselves enter the piece in close to real time.
A nasty bug, triggered by an unusual submission format, convinced us during the final week to reduce the live system's error surface. We also moved from Ableton Live to Steinberg Nuendo for faster and more flexible stem export. We exported synchronized stems for each speaker instead and played them back from a fixed file set. The daily rebuild of the sampler preserved most of what we wanted from the live system: every time we re-exported, the composition altered because each note pulled a different contributor. Playback became reliable enough to run unsupervised.
The initial musical direction was closer to minimalism than to what the piece became. Vocal arpeggios running up and down the stairwell, a sparse layer of activity distributed by register. What emerged was a hybrid between that and a contemporary choral idiom, with Ligeti as the primary anchor in the cluster-writing lineage and Holly Herndon's PROTO as a conceptual reference more than a sonic one.
The five-floor register logic survived the production process but softened. The original plan was clean range separation by floor. What we ended up with is closer to a pyramidal distribution: each floor foregrounds its dominant register, but all layers carry through the whole system via controlled send levels. Lower floors lean on the tenor material while keeping mid and high content present; upper floors sit in the soprano register while retaining a subtle presence of everything below. The result reads as more organic and, in the finished piece, more faithful to the way voices actually carry in a stairwell.
Sound system
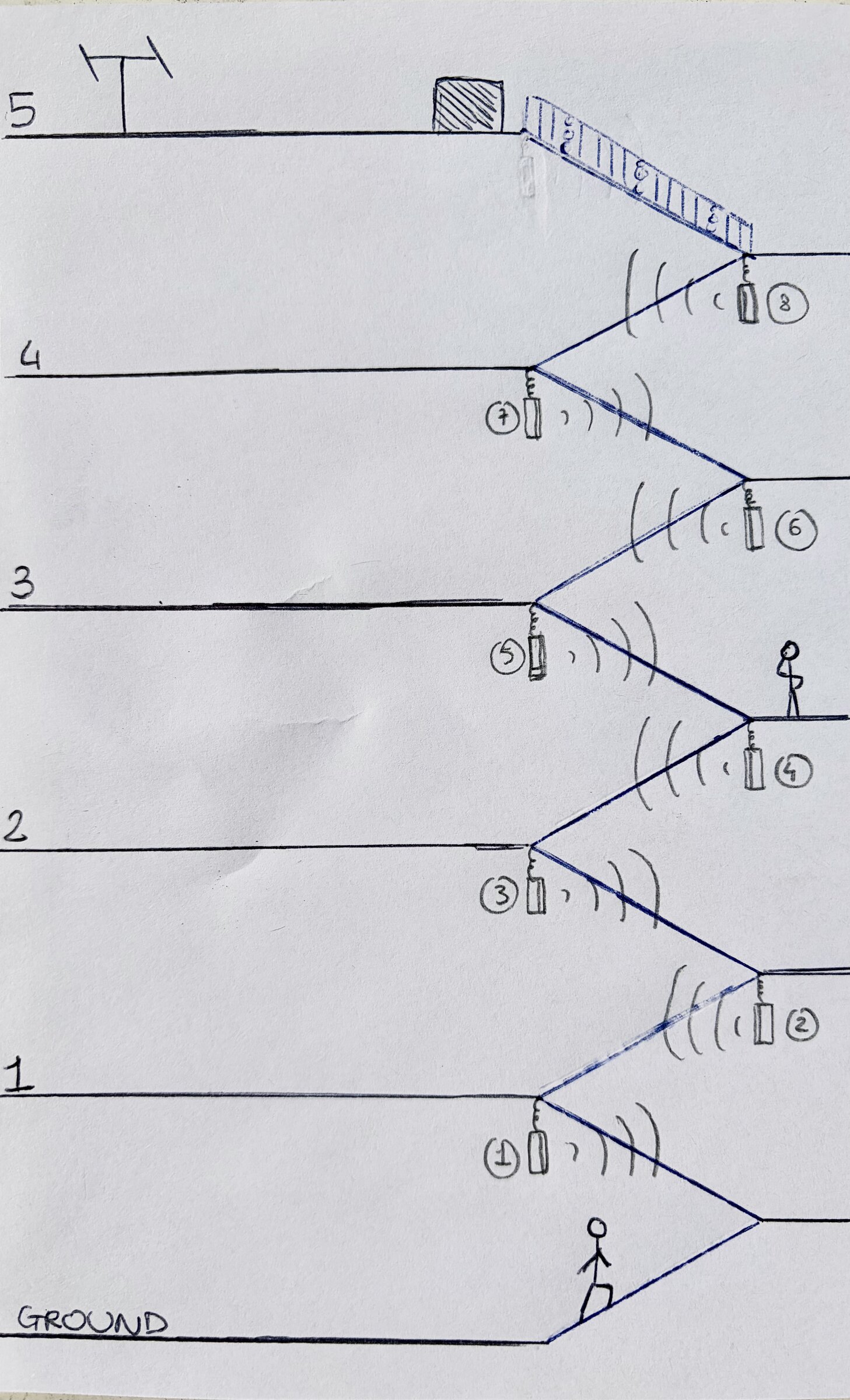
The physical conditions of the stairwell are what you'd expect: hard plastered surfaces, 2–3 second reverb tails, flutter echo between landings, strong vertical coupling between floors. The system was designed to work with those conditions.
We mapped the stairwell as eight listening zones rather than five floors, placing two speakers per floor across floors one through four. The fifth floor opens onto the rooftop terrace and has no dedicated speakers; it receives the sound that collects from below, which has become one of the more atmospheric moments of the piece. Speakers are d&b 44S, chosen for their 90° × 30° dispersion, which keeps separation between floors in a reflective space while still producing a continuous field, and for their minimal visual footprint. The stairwell is lived-in architecture, and the speakers had to sit within it without drawing attention. The 4.5" drivers are closer in scale to a human voice than to a typical PA system, a deliberate choice that shaped both the perceptual character of the piece and the mounting logic. Each speaker is suspended from rigging points and aligned with average ear height at the landings, calibrated at roughly 50–60 dB SPL per speaker. We wanted the system to register at a vocal scale, not a PA scale.

Playback runs from a Mac Mini in QLab through a MOTU Ultralite Mk4 into two d&b amplifiers (a D80 for the lower floors, a 5D for the upper ones), split for headroom on the longer cable runs. All eight channels originate from the same interface, so sync is sample-accurate at the source. We prototyped an earlier version on a Bela Gem Multi running custom C++ before moving to the QLab setup for stability across a week-long run.
Cable lines run vertically from the top of the building, branching floor by floor. At Furio's suggestion, the cabling was intentionally left visible and extended with additional non-functional lines, producing a dense vertical texture that reads as signal infrastructure running through the stairwell. A technical operator is on site throughout Convey's opening hours, with backups for all critical components.
Tuning and acoustics



The 2–3 second reverb became a compositional asset: it extends the tails of the vocal material and glues the layers together across floors. The speaker directivity carries the intelligibility, the room carries the blend. No acoustic treatment was introduced; the small drivers' limited low-end extension handled most of the usual stairwell problems on its own. Per-floor EQ was applied by ear during installation, primarily cutting low frequencies and more aggressively on the lower floors where the tenor material concentrates energy in the low-mid range.
Documentation and recording


The installation is temporary, so the documentation recording was planned carefully, with the intent of producing source material for eventual release in formats ranging from linear stereo mixes to more spatial or interactive versions. Recording happened in situ during off-hours. Two ORTF pairs (110°, 17 cm) were used: a Schoeps MSTC 64 pair at the acoustic center of each landing at ear height, capturing the perspective of a visitor standing still, and a Sennheiser MKH 8040 pair positioned off-center and tilted upward to capture a more dynamic perspective closer to the experience of ascent. Both pairs ran into a Sound Devices MixPre-10T.
Contribution and credit
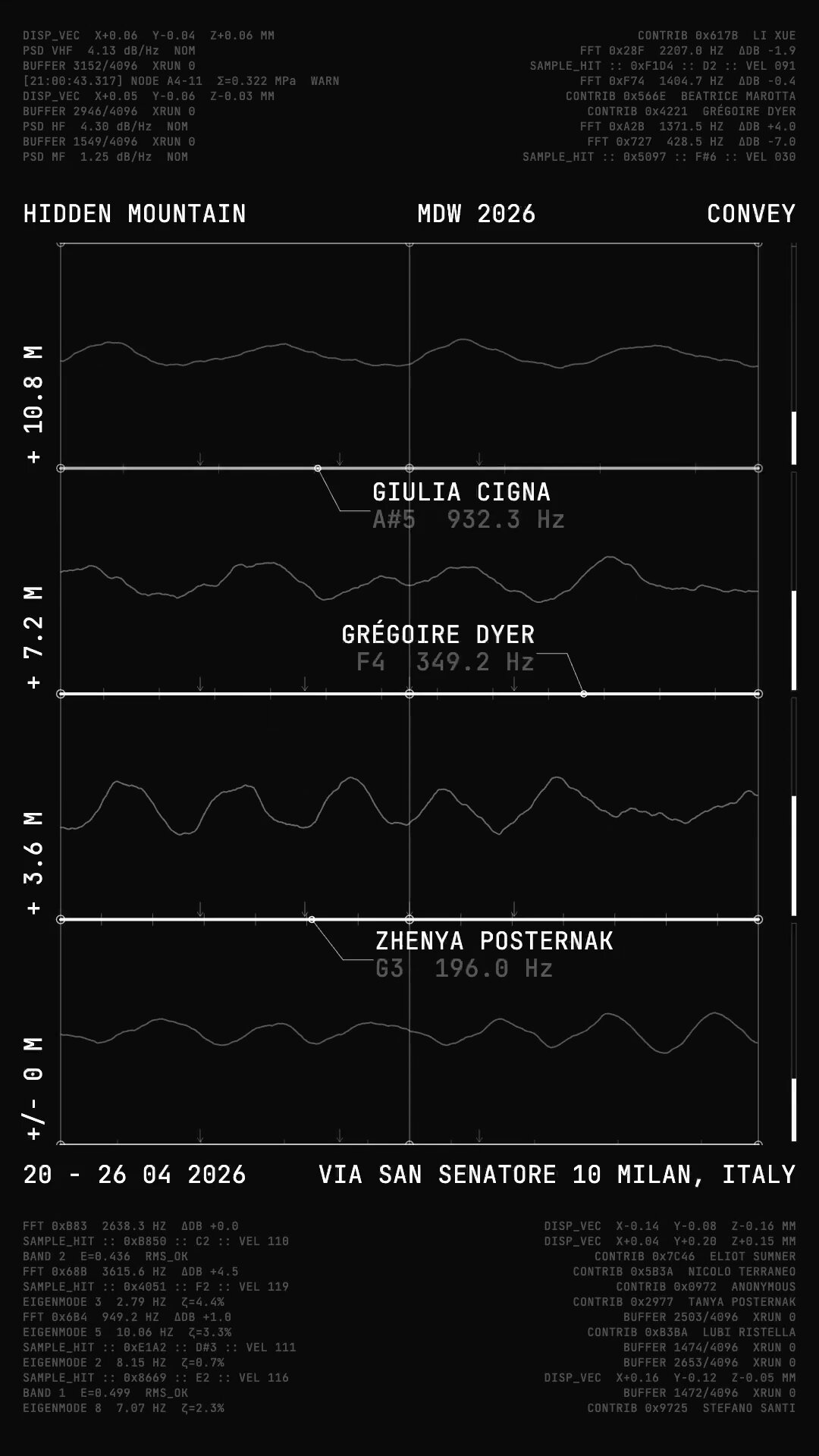
Condominio is built from fifty-two voices as of the installation's first day. Contributors were gathered publicly through open outreach, ranging from close collaborators of the studio to people at one or two removes through Convey's and Hidden Mountain's networks.
Every contributor is named. The mapping.json file produced by the build pipeline pairs every note in the instrument with the contributor whose voice plays it, and a visualizer we built surfaces the contributor currently playing in real time, used in press and social material about the piece. Printed credits distributed at the installation list every participant in full.
We avoided heavy on-site visual treatment. Stairwells are circulation spaces, not viewing rooms, and the last thing we wanted was to encourage crowds to stop mid-ascent to read wall text. The participatory side of the piece reads most clearly in the documentation, communications, and visualizer, not in the installation itself, a tradeoff we'd revisit in a future iteration.



Credits
- Thomas Feriero: composer, software, creative director.
- Luca Rigat: sound system designer, field recordings.
- Furio Montoli: installation designer.
- Giulia Spitaleri: producer.
- Vocals: Adriana Carlot, Alexander Inggs, Anna T., Aurora Tiepolo, Azzurra Pasta, Beatrice Marotta, Carlo di Blasi, Cecilia Gesuato, Eliot Sumner, Emilia Pezzini, Francesco Napoleone, Furio Montoli, Giorgia Massari, Giulia Cigna, Giulia Feriero, Giulia Spitaleri, Giulio Montoli, Grégoire Dyer, Ha Ra, Jihyung Park, La V, Li Xue, Livia Peirce, Luca Rigat, Ludovica Rigat, Luigi Cianciaruso, Matilde Bonanni, Mattia Lolli-Ghetti, Michele Zanuso, Nicolo Terraneo, Oscar Morgan, Pablo Tapia Pla, Severin De Courten, Stefano Santi, Tanya Posternak, Thomas Legler, Tommaso Gesuato, Una Kviese, Zhenya Posternak, and 13 anonymous contributors.
- Photos & videos by Luigi Calfa, Tomaso Lisca, Carlo di Blasi, Furio Montoli.